

NVIDIA and TSMC Collaboration: GPU-Accelerated TCAD Simulations with AI Integration
Original Article by SemiVision Research

NVIDIA and TSMC Collaboration: GPU-Accelerated TCAD Simulations with AI Integration
NVIDIA and TSMC have teamed up to infuse GPU-accelerated computing and AI into semiconductor TCAD (Technology Computer-Aided Design) simulations, dramatically boosting performance and accuracy from the atomic scale to device scale. By leveraging the CUDA parallel computing platform and its rich ecosystem of libraries (such as cuDNN, OptiX, AmgX, cuSolver, etc.), the partnership has built a comprehensive TCAD “factory” workflow where various physics simulation components are accelerated by GPUs . In addition, NVIDIA’s AI frameworks like PhysicsNeMo enable physics-informed machine learning models to serve as efficient surrogate models within simulations, further enhancing the coherence and speed of multi-scale simulations. This collaboration allows TSMC to conduct virtual experiments in process development much faster, simulating complex manufacturing processes and device behaviors in a shorter R&D cycle and at lower cost. It achieves a high fidelity of physical phenomena while unleashing innovation by exploring design spaces that were previously impractical to simulate in detail.
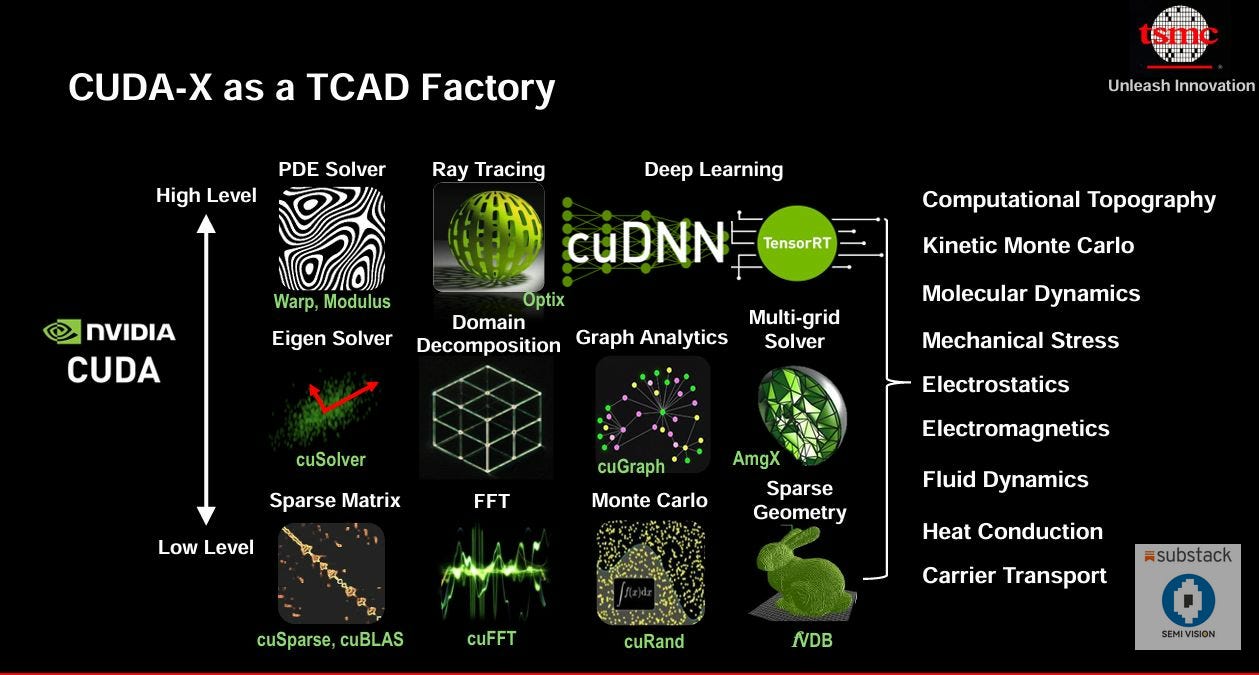
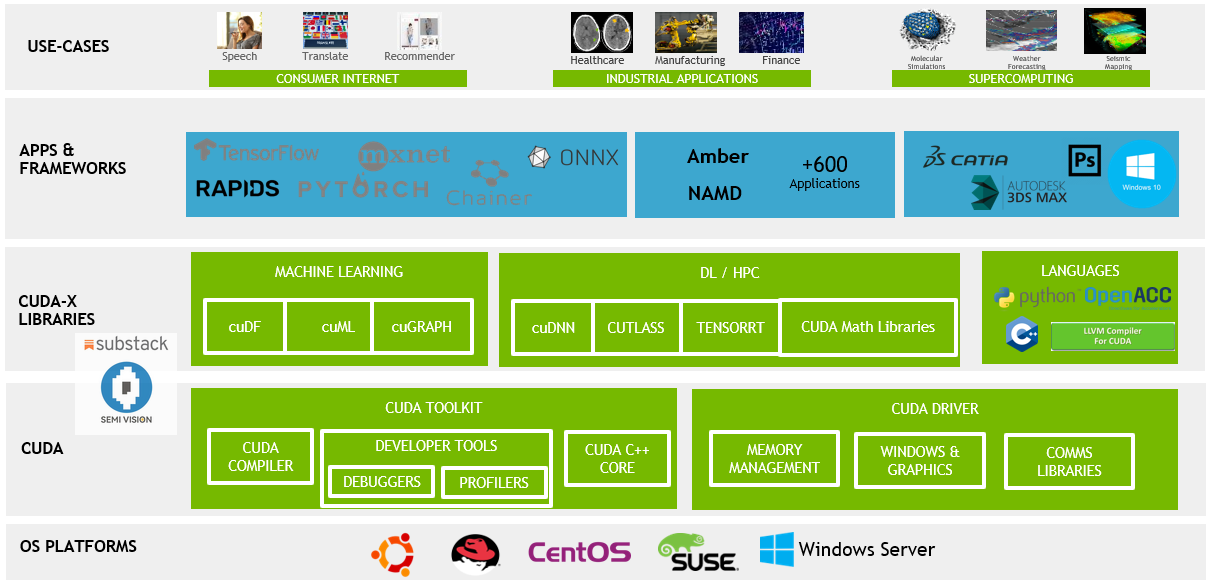
CUDA-X is a collection of high-performance libraries and tools built on NVIDIA’s CUDA architecture, and it serves as a toolkit factory underpinning the TCAD simulation workflow. At the high-level application layer, the core algorithms required by various TCAD modules map to GPU-optimized components provided by CUDA-X. For example, solving PDEs in device simulations (such as Poisson or diffusion equations) can leverage multi-grid solver libraries (like AmgX) or linear algebra solvers (like cuSolver) to accelerate the solution of large linear systems. Simulations involving stochastic sampling (such as Monte Carlo for dopant implantation) can exploit CUDA’s parallel cores to greatly speed up sample generation and statistical averaging. If a simulation requires large-scale matrix operations or FFTs, the corresponding libraries cuBLAS (dense linear algebra), cuSparse (sparse matrices), and cuFFT (Fast Fourier Transform) provide ready-to-use, GPU-optimized implementations . For computations related to optics and ray tracing (e.g. computational lithography or the topography simulation described above), the OptiX library functions as a high-speed ray-tracing engine. For training and inference of ML models in the loop, the cuDNN deep learning library and TensorRT ensure neural network computations are efficient on GPUs. By assembling these CUDA-X components, all key steps in the TCAD flow — from atomic-scale molecular dynamics and kinetic Monte Carlo simulations, to device-level electromagnetic/thermal calculations, and up to wafer-level process topography and mechanical stress modeling — can run with industry-grade performance. This “factory-style” approach means developers can build TCAD tools like stacking Lego blocks, invoking proven GPU-accelerated modules without reinventing algorithms from scratch. Through the NVIDIA-TSMC collaboration, the CUDA-X ecosystem has been fully utilized to upgrade TSMC’s internal simulation software with GPU capabilities, yielding speed-ups on the order of ten-fold or more in many cases . Ultimately, this not only shrinks the computation time for simulations, but also expands the scale and complexity of problems that can be simulated (for instance, allowing larger chip areas to be modeled within a given time or enabling exhaustive statistical variation analysis). It greatly enhances the value of TCAD in advanced process development.

Deep Potential Molecular Dynamics uses deep learning to create surrogate models of interatomic forces, achieving the speed of classical force fields with the high accuracy of first-principles calculations . It employs deep neural networks such as graph neural networks (GNNs) to represent the potential energy surface between atoms. These networks are trained for each material or application to closely match reference data (e.g. DFT) on atomic energies and forces. Once trained, the deep potential model can be used in large-scale MD simulations (in inference mode), with GPUs accelerating the force calculations for every atom in parallel. In semiconductor processing, DPMD can be applied to simulate phenomena like atomic diffusion, defect evolution, or interface reactions, providing nanoscale insight into material properties. This helps predict details such as dopant diffusion pathways or crystal structural stability. With GPU acceleration, TSMC can complete previously time-prohibitive atomistic simulations in practical timeframes, and feed those results into subsequent device and process-level models, ensuring that higher-level simulations rest on a solid physical foundation.

Summary and Future Trends of CNN and GNN
• CNN has reached maturity in visual tasks, with potential extensions to broader computer vision and reinforcement learning applications.
• GNN is rapidly evolving and is expected to play critical roles in drug discovery, recommendation systems, and social network analytics.
These neural network architectures will continue to evolve and expand, enabling more effective solutions to increasingly complex data and real-world problems

Summary and Future Trends of NN

For Paid Members ,SemiVision Research will discuss following topics
TCAD Problem Scale in Semiconductor field (TSMC Viewpoint)
CuLitho accertate the advanced node improvement (ASML TSMC Nvidia)
PIML Power by NVIDIA’s PhysicsNeMo
GPU-Accelerated Multi-Grid Solvers
GPU-Accelerated topographical profile
