

2025 GTC Preview: The Evolution of Nvidia GPUs and Switches from the Perspective of Chip and Network Convergence
Original Article by SemiVision Research


Before reading this article, if you haven’t seen our previous Nvidia GTC Preview, you can refer to this article.
Nvidia GTC AI Conference Preview: GB300, CPO switches, and NVL288
AI Cluster Concept Explanation
An AI Cluster is a high-performance computing (HPC) architecture specifically designed for AI training and inference. It consists of multiple GPUs, TPUs, or other AI accelerators, forming a large-scale computing resource that enhances the speed and efficiency of AI model training.

Key Components of an AI Cluster
1. Hardware Architecture
An AI Cluster typically consists of the following key components:
• GPU / TPU / ASIC Accelerators: Core computing units for deep learning and AI training, such as NVIDIA H100, Google TPU, and Cerebras Wafer Scale Engine (WSE).

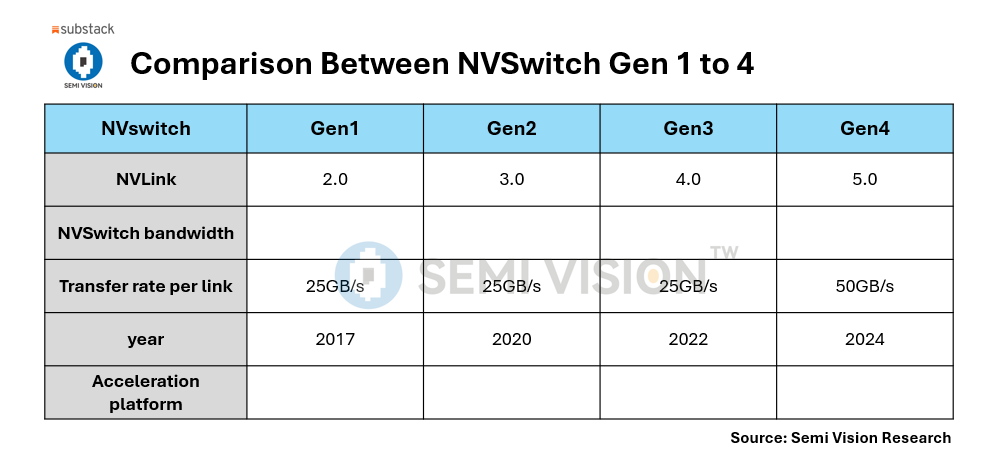
High-speed Networking (InfiniBand, Ethernet, NVLink) – Low-latency, high-bandwidth communication between nodes.



Memory– Fast access storage for AI computations.
Storage – High-throughput storage for datasets and model checkpoints.


2. Software Components
AI Frameworks – Libraries for training and deploying AI models.
Containerization– Resource management and deployment at scale.
Cluster Management – Orchestrates workload distribution across nodes.
Data Management – Handles large-scale data access and storage.
3. Power & Cooling
Power Supply Units – Handles high-energy demands of AI hardware.
Air Cooling / Liquid Cooling / Immersion Cooling – Prevents overheating in dense AI clusters.
4. Security & Access Control
Authentication & Authorization– Secure access to cluster resources.
Data Encryption & Secure Storage – Protects sensitive AI models and datasets.
AI Large Language Model Arms Race: Compute Power, Models, and Future Trends
In recent years, the development of generative AI has advanced rapidly, and competition among AI large language models (LLMs) has become increasingly intense. As tech giants like OpenAI, Meta, and xAI launch the next generation of AI models, the race for compute power, chip technology, and model architecture has evolved into a true “arms race.”
At the core of this competition lies the immense computational power required for AI training and inference. Companies are not only designing more advanced models but also investing heavily in GPUs and custom ASICs (such as Tesla Dojo) to optimize training and deployment, ensuring the best balance between performance and cost.
1. The Competitive Landscape of AI Tech Giants
The key players in the LLM field today include OpenAI, Meta, and Elon Musk’s xAI. These companies have adopted different strategies and technological choices regarding training scale, chip procurement, and release schedules.
OpenAI: Scaling Up with GPT-6 and GPT-7
As a leading AI research organization, OpenAI plans to launch GPT-6 in 2026, followed by GPT-7 in 2027. GPT-6 is expected to be trained using 150,000 NVIDIA H100 GPUs, while GPT-7 will leverage 100,000 B200 GPUs, significantly enhancing both model performance and inference efficiency. This demonstrates OpenAI’s commitment to maintaining its leadership in AI training.
OpenAI just released GPT-4.5 and says it is its biggest and best chat model yet
Meta: Expanding AI in the Open-Source Ecosystem
Meta has taken a different approach by emphasizing open-source AI development. Llama 5 is set to launch in September 2025, using 100,000 H100 GPUs for training, while Llama 6, expected in August 2026, will leverage 300,000 B200 GPUs to enhance its capabilities. By doing so, Meta aims to solidify its competitive edge in the open-source AI market, attracting more developers and enterprises to adopt its models.
xAI: Pushing Compute Boundaries with Grok 4 and Grok 5
Elon Musk’s xAI is also making aggressive moves in the AI space, aiming to challenge OpenAI with its “Grok” series of models. Grok 4 is scheduled for release in July 2025, trained on 400,000 B200 + H200 GPUs, while Grok 5, expected in February 2026, will utilize 800,000 B200 GPUs alongside Tesla’s custom Dojo 2 chips. This highlights xAI’s ambition to build its own AI training ecosystem.
Elon Musk’s xAI raising up to $6 billion to purchase 100,000 Nvidia chips for Memphis data center
For Paid Members , SemiVision Research will discuss topics on
The Compute Power Arms Race: AI Chips Take Center Stage
Tesla Dojo: Elon Musk’s Custom AI Training Chip
Cerebras and the Wafer-Scale Engine (WSE)
The Future Impact of the AI Arms Race
The advancement of AI clusters relies heavily on the progress of scale-out architectures. (Optical Interconnection)
High-Speed Networking
AI S-Curve Development Model
AI Training / AI Inference
Edge Computing: Bringing AI Inference Closer to the Data Source
The Future of AI Inference
Supercomputing (HPC)
Autonomous Vehicles & Smart Robots
The Role of AI in Humanoid Robots