

Phison Electronics: Memory Shortage Is the Real AI Killer, Not GPUs
Original Article By SemiVision [Reading time: 15 mins]

In early 2026, the semiconductor industry is gripped by an unprecedented memory supply crisis. Phison Electronics CEO Pan Chien-cheng (also known as K.S. Pua in English media), in a candid interview, described the situation not as a temporary fluctuation but as a structural, long-term shortage expected to persist at least until 2030—and potentially a full decade according to his broader industry outlook.

AI has evolved from hype into an absolute necessity, fundamentally reshaping the supply-demand balance and placing immense pressure on consumer electronics, while opening new opportunities for innovative players like Phison.
This article is adapted and expanded from the February 13, 2026 episode of 年代向錢看 (Time to Make Money)
Memory Supply-Demand Imbalance: An Unprecedented Seller’s Market
Pan describes the current market as “the most aggressive seller’s market in electronics history.” Both DRAM and NAND Flash are in severe shortage. Memory manufacturers now demand prepayment for three years of supply—an extreme condition never seen before, even in dealings between TSMC and NVIDIA.
Phison itself struggled to secure DRAM for expanding 800 Gen5/Gen6 test servers, forcing direct negotiations with original manufacturers; traditional distributors have no stock left. Customer fulfillment rates hover below 30%, leaving Pan feeling like a “memory beggar,” repeatedly making the same pleas to suppliers.
Pricing has skyrocketed. eMMC 8GB modules jumped from $1.5 in early 2025 to $20 now, with automotive-grade versions nearing $24–30. The most aggressive pricing comes from U.S. and Chinese suppliers, as global competition for limited capacity intensifies.
Industry forecasts indicate this imbalance will continue through 2030. While NAND bit growth for 2026 is projected in the high single digits to teens (constrained by supply), real demand far exceeds this—”much, much higher,” as Pan puts it. Major players like Samsung, Micron, Kioxia, SK Hynix, and YMTC Memory are announcing expansions, but ramp-up takes at least two years, and equipment shortages create bottlenecks—one slot per tool. Chinese capacity additions (YMTC and CXMT) will help marginally (3–5% of global output initially), but internal demand in China prioritizes domestic needs, limiting export relief and preventing cheap dumping.
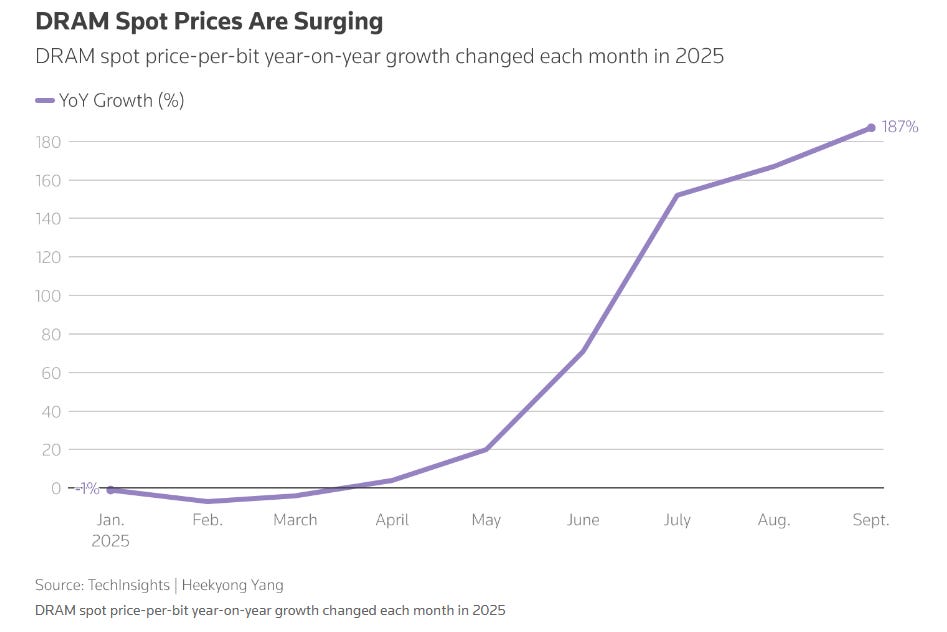
Memory makers, scarred by losses from 2020–2025, remain cautious on expansion. CEOs now enjoy guaranteed profits for the next 3–5 years, but shareholder pressure focuses on market cap growth rather than aggressive scaling.

AI as True Demand Driver, Not Speculation
Pan stresses that AI is genuine need, not bubble. Unlike the VR boom that fizzled because it wasn’t essential, AI has driven the industry since 2022—only three and a half years in, yet poised for decades-long dominance, rivaling PCs (40 years), smartphones (20+ years), and the internet (~20 years).

The explosive example is NVIDIA’s upcoming Vera Rubin architecture, focused on inference. Each GPU requires over 20TB of SSD. If 10 million units ship by late 2026, that’s roughly 200 Exabytes—about 20% of last year’s global NAND output—and this excludes the massive additional storage for generated data. Industry estimates suggest even higher impact: projections indicate Vera Rubin systems could consume tens of millions of terabytes in NAND just from NVIDIA alone in coming years, intensifying shortages.
Inference phase is where true explosion occurs. Training uses limited servers with huge data volumes; inference involves smaller per-query loads but vastly more servers. KV Cache demands are enormous. Current shortages stem mainly from cloud; edge/on-device demand hasn’t fully materialized. Once cloud claims priority (deeper pockets), edge gets squeezed; when supply eases slightly, edge demand surges, keeping overall capacity insufficient.
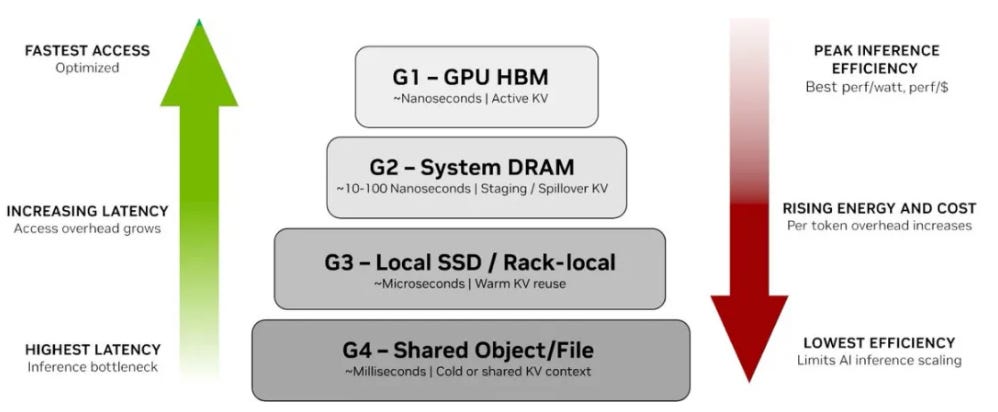
KV Cache is often described as the “short-term memory” of an AI model (particularly large language models, or LLMs, based on the Transformer architecture). It stores previously computed key-value (K-V) pairs from the self-attention mechanism, preventing redundant calculations for past tokens during autoregressive generation (i.e., when the model predicts one token at a time). Without KV cache, every new token would require recomputing attention over the entire input sequence, leading to quadratic time complexity and massive inefficiency. By caching these intermediate results, inference speed improves dramatically—often by orders of magnitude for long contexts—while enabling the model to “remember” earlier parts of the conversation or prompt seamlessly.Depending on the memory hierarchy and performance requirements, KV cache can be placed across different storage tiers. These tiers trade off speed, capacity, cost, and power efficiency:
G1: GPU HBM (High-Bandwidth Memory)
This is the fastest tier (nanosecond-scale access) and serves as the primary, “active” KV cache. It holds the most latency-critical data directly involved in ongoing token generation. HBM offers peak bandwidth and efficiency but has very limited capacity (tens of GB per GPU at most), making it the scarcest and most expensive resource.G2: System DRAM
Acts as a staging buffer or overflow area when the KV cache exceeds HBM limits. It provides much larger capacity than HBM (hundreds of GB per server) with access latencies in the tens to hundreds of nanoseconds. Data is often evicted from G1 to G2 and can be quickly re-staged back when needed, though with some bandwidth and power penalties compared to pure HBM access.G3: Local SSD (or rack-level storage)
Serves as “warm” KV cache for data reused over shorter timescales but not immediately active. Access is in the microsecond range (much slower than DRAM), but capacity scales to terabytes per node. This tier is ideal for temporarily offloading less-hot context, especially in single-node or rack-local setups, reducing recomputation while keeping latency manageable for many inference workloads.G4: Shared / networked storage (largest capacity, cross-node)
The highest-capacity tier (petabytes possible across clusters), suitable for “cold” artifacts, historical context, long-term results, or shared multi-agent/agentic scenarios. It enables persistence and cross-node sharing but introduces millisecond-scale latency, making it unsuitable for real-time token generation without careful pre-staging. Emerging solutions (like NVIDIA’s Inference Context Memory Storage platform) optimize G3–G4 transitions for better efficiency in large-scale deployments.
This tiered approach—popularized in recent NVIDIA architectures (e.g., for Vera Rubin and beyond)—addresses the growing KV cache bottleneck in long-context, high-batch, or agentic AI workloads. As context windows expand (to millions of tokens) and inference shifts toward multi-turn, persistent sessions, intelligently moving KV data across G1–G4 minimizes stalls, maximizes GPU utilization, and controls costs. For instance, active generation stays in G1, overflow spills to G2, warm reuse hits G3, and durable/shared history lives in G4—often with orchestration tools pre-fetching data to avoid decode-phase delays.In summary, KV cache turns the model’s “memory” into a hierarchical, optimizable resource, balancing ultra-low latency for hot data against massive scale for colder context in the AI era.


Below We will share:
Devastating Impact on Consumer Electronics
Phison’s Unique Strategy: Value Creation Over Raw Production
Long-Term Bets: Space, Automotive, and Focused Execution
Final Thoughts: The Real AI Bottleneck Is Memory, Not Compute
Future Memory Development Trends (2026–2030) and Key Considerations
What to Watch and Key Considerations in 2026
